De GPU Local a Agentes de Código
Nas últimas três ou quatro semanas, estive testando tecnologias de IA na prática. Este post é um resumo técnico — antes de falar sobre qualquer ferramenta, prefiro testar, entender o que está acontecendo por baixo e tirar minhas próprias conclusões. IA é um campo amplo, ainda há muito a explorar, mas já consigo extrair valor real para produtividade.
Rodando modelos locais com Ollama
A primeira decisão foi saturar minha GPU RX6600 com 8GB de VRAM rodando modelos locais. O objetivo não foi fazer benchmark — foi entender o limite real do hardware.
Com o Ollama, o fluxo é simples: você baixa modelos compatíveis e roda localmente. No meu caso, o limite prático ficou em modelos até 8B de parâmetros. GPUs AMD exigiram configuração extra via Vulkan — diferente das NVIDIA, que têm suporte nativo via CUDA na maioria dos frameworks de inferência.
O que significa "8B"? O número de parâmetros de um modelo (ex: 8 bilhões) representa, de forma simplificada, a quantidade de pesos que foram ajustados durante o treinamento. Mais parâmetros geralmente significa maior capacidade de raciocínio e compreensão, mas também mais memória necessária para rodar.
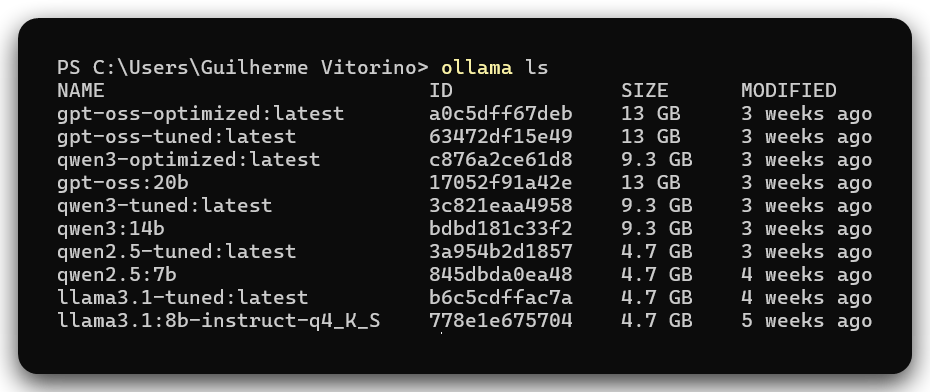
Mesmo conhecendo o limite da GPU, testei modelos um pouco maiores ajustando temperatura e contexto via Modelfile. O que acontece nesses casos é que o processamento é dividido entre GPU e RAM — e o resultado é resposta muito lenta, na prática inviável para uso contínuo.

Interface local com Open WebUI
Com os modelos rodando, conectei tudo a uma instância Docker do Open WebUI para ter uma interface de chat local. Vale alinhar expectativa aqui: não vira um "ChatGPT local" equivalente aos modelos de ponta pagos.
Um modelo 7B/8B local consegue ajudar em tarefas específicas — responder dúvidas simples, gerar código pequeno, resumir texto — mas sofre em planejamento longo, contexto extenso e raciocínio mais complexo. A experiência varia bastante dependendo do modelo, quantização, contexto configurado e, principalmente, da qualidade do prompt.
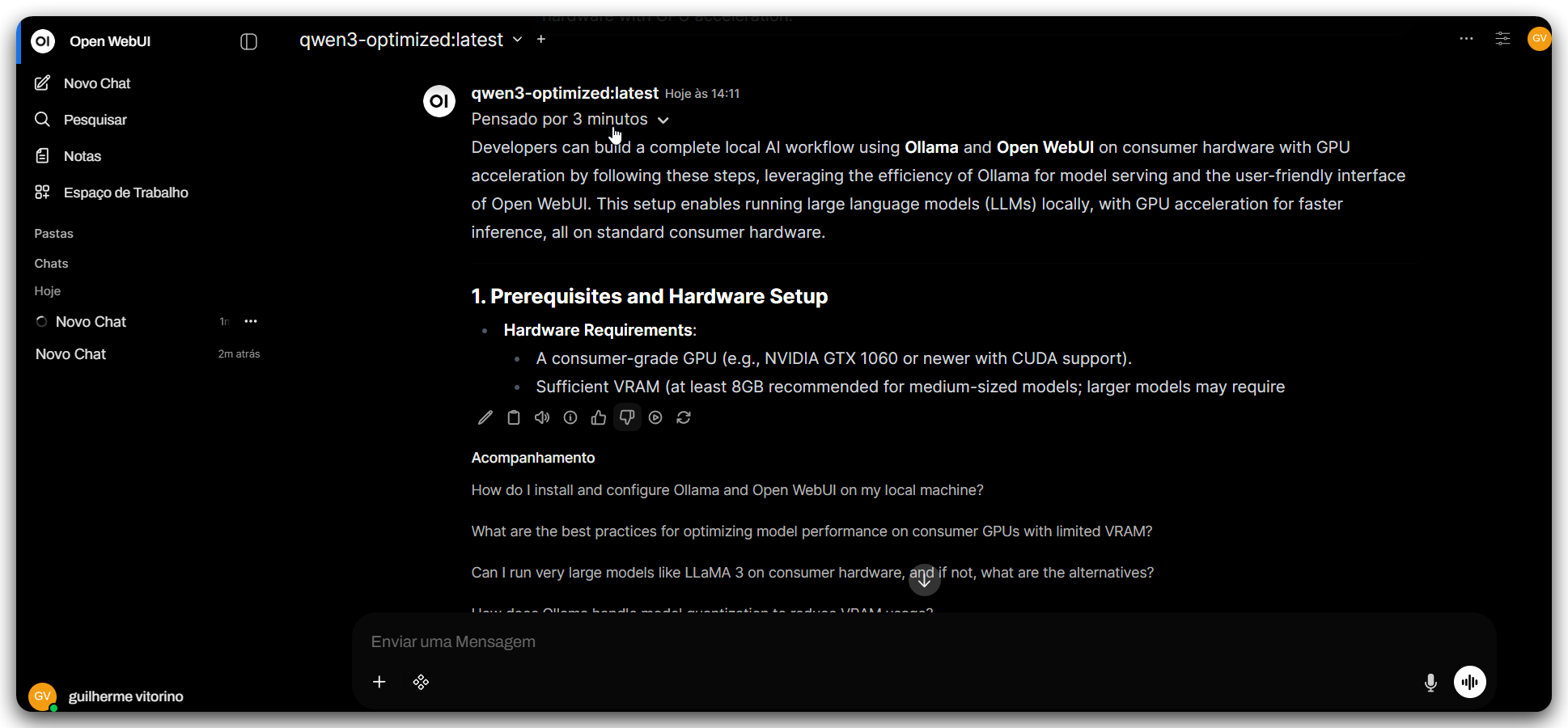
ComfyUI: geração de imagem/vídeo e compatibilidade AMD
Testei o ComfyUI com modelos especializados em geração de vídeo e imagem. Aqui os problemas com AMD voltaram com força: testei versões com ROCm, ComfyUI-Zluda e o ComfyUI Desktop, mas o erro era sempre o mesmo — os pipelines esperavam encontrar uma GPU NVIDIA.
Por fim consegui rodar instalando via Stability Matrix com backend DirectML — mas não sem custo: tive que fixar uma versão antiga do ComfyUI porque as mais recentes quebravam na geração. E mesmo rodando, a sensação é que o DirectML não usa todo o potencial da GPU. Gerou, mas com ressalvas.
É o padrão com AMD nesse ecossistema: você chega lá, só que pelo caminho mais longo. Ainda quero voltar a esses modelos em outro projeto — provavelmente testando uma GPU NVIDIA via cloud pay-as-you-go para ter uma referência real de comparação.
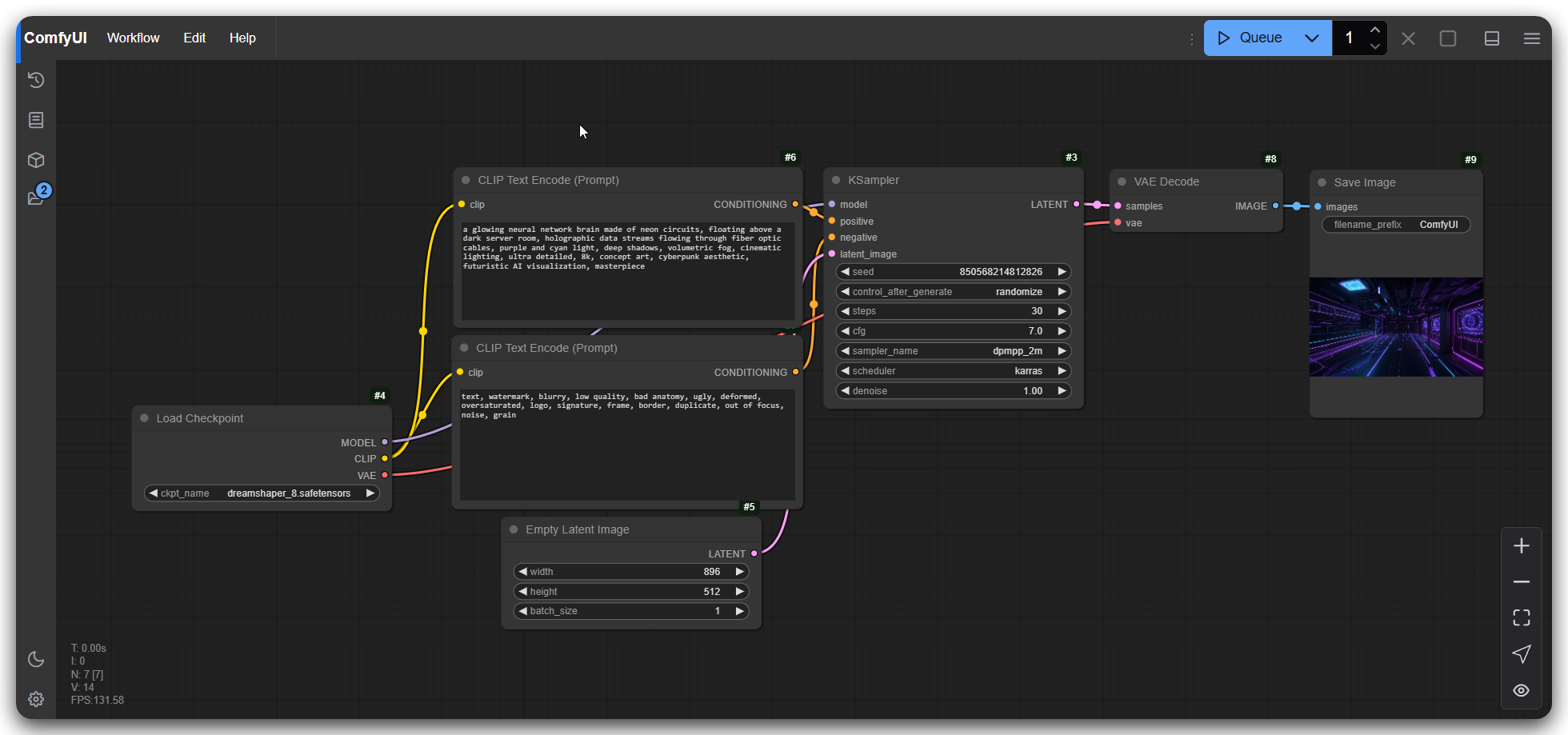
Agentes de código: onde o harness faz diferença
Para geração de código, o uso de agentes muda o jogo. O harness — que aqui entendo como a camada que envolve o modelo: como o agente monta o contexto, qual parte do projeto ele passa para a LLM, como estrutura o prompt — influencia diretamente a qualidade do resultado, independentemente do modelo usado.
Testei os seguintes agentes: Aider, Opencode, Crush e Claude Code.
Como cada agent possui um nível diferente de visibilidade sobre o que realmente envia para a LLM, implementei um proxy simples em Go para interceptar e normalizar os logs. O proxy não interfere na resposta — só registra. O código do proxy, os logs completos e o ai-runtime estão no repositório [link].
Alguns agents já têm flags nativas de visibilidade:
- Aider:
--verbose --no-prettypara request/response raw no terminal;--llm-history-filepara dump completo de cada turno. - Crush:
--debugou"options": { "debug": true }no crush.json, que expõe payload JSON e tool calls. - OpenCode:
--log-level DEBUG, mas o payload bruto nem sempre aparece sem proxy. - Claude Code: sem flag de debug para payload LLM exposta publicamente — exige proxy obrigatoriamente, por isso usei o LiteLLM como camada intermediária.
Os números abaixo são da primeira requisição de cada sessão — suficientes para ver a filosofia de contexto de cada agent antes de qualquer tool call.
| Agent | Endpoint | Prompt tokens (est.) | Thinking | Concluiu | Filosofia |
|---|---|---|---|---|---|
| Aider | /api/generate |
~2.698 | Não exige | ✓ | Patch determinístico |
| OpenCode | /v1/chat/completions |
~2.576 | Não envia | ✓ | Token economy |
| Crush | /v1/chat/completions |
~5.477 | Exige — falhou | ✗ | Execução contínua |
| Claude Code | /v1/chat/completions |
N/A | Exige — falhou | ✗ | Cognição distribuída |
Prompt tokens estimados na primeira requisição de cada sessão, capturados via proxy. N/A indica que a sessão falhou antes de completar a primeira chamada de código.
Aider
Foi capaz de concluir a tarefa sem erro de compatibilidade — dentro das limitações do modelo local. Minha hipótese inicial era que o harness do Aider passa menos contexto ao modelo — e pelos logs, isso se confirma parcialmente. O Aider estimou prompt_tokens_est: 2698 para a mesma tarefa em que o OpenCode usou 746.
A diferença está na natureza do contexto. O Aider monta um prompt extremamente procedural, cheio de exemplos de formato SEARCH/REPLACE e regras de edição, mas não injeta o runtime inteiro do agent como faz o Claude Code. Com modelos 8B, contexto menor e mais focado tende a produzir resultado mais coerente do que uma janela enorme com muita instrução arquitetural que o modelo não consegue seguir de ponta a ponta.
O padrão de edição do Aider é revelador nos logs: ONLY EVER RETURN CODE IN A SEARCH/REPLACE BLOCK e EXACTLY MATCH. Isso reduz o espaço de decisão do modelo a uma transformação textual determinística — ao invés de pedir que o modelo pense arquiteturalmente, o Aider pede que ele produza um patch bem formado. Para modelos menores, essa restrição é uma vantagem real.
Há uma razão estrutural para isso: o Aider usa o endpoint /api/generate do Ollama — a API nativa — enquanto os outros três usam /v1/chat/completions, o endpoint de compatibilidade OpenAI. O /api/generate não tem o contrato de tool_calls, então o Aider opera sem tool execution por design do endpoint, não por limitação do modelo. O que parece uma fraqueza (sugerir shell commands em vez de executá-los) é uma consequência direta de uma escolha arquitetural que também elimina toda a complexidade de tool calling do espaço de decisão do modelo.
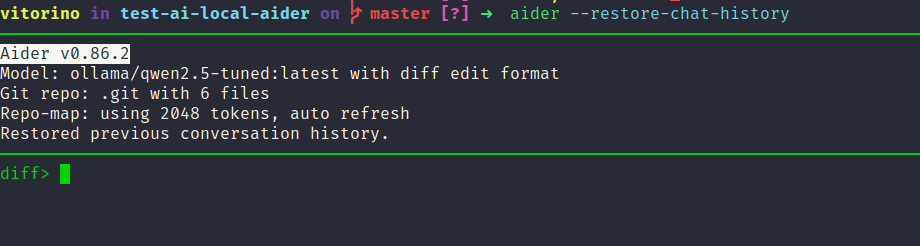
Os logs mostram também um pipeline de commit message separado:
"You are an expert software engineer that generates
concise, one-line Git commit messages"System prompt da segunda requisição do Aider — pipeline separado, invisível para o usuário.
O Aider trata cada stage como uma tarefa especializada, o que é uma forma de multi-agent implícita sem orquestração declarativa.
Opencode
Com os mesmos modelos locais, o Opencode conseguiu concluir a tarefa. O detalhe mais interessante nos logs do OpenCode é o prompt dual: a primeira requisição (prompt_tokens_est: 746, latency_ms: 1860) é o gerador de título da thread — um micro-agent separado com sistema prompt próprio, focado só em gerar uma linha descritiva da conversa. A segunda é o agent de código principal (prompt_tokens_est: 2576). Essa separação de responsabilidades é exatamente o que permite ao OpenCode manter o contexto do agent principal mais enxuto.
Nos logs de execução do agent principal dá pra ver o padrão de tool use concorrente funcionando: múltiplas chamadas de edit e write sendo feitas em sequência dentro de um único turno, com o model recebendo os resultados intermediários acumulados no histórico.
O modelo foi incrementando o projeto arquivo por arquivo — app.js, routes/index.js, controllers — mas sem coordenação global. Isso aparece nos logs de duas formas distintas. A primeira é perda de estado: "Offset 14 is out of range for this file (8 lines)" — o modelo tentou editar uma posição que não existia mais no arquivo, porque o arquivo havia mudado em turnos anteriores.
O OpenCode não instrui reasoning explícito no payload — não envia thinking: true nem força CoT no prompt. O Qwen2.5 funciona com ele porque o prompt é compacto o suficiente para que o modelo consiga executar as instruções sem precisar de uma cadeia de raciocínio longa antes de cada ação.
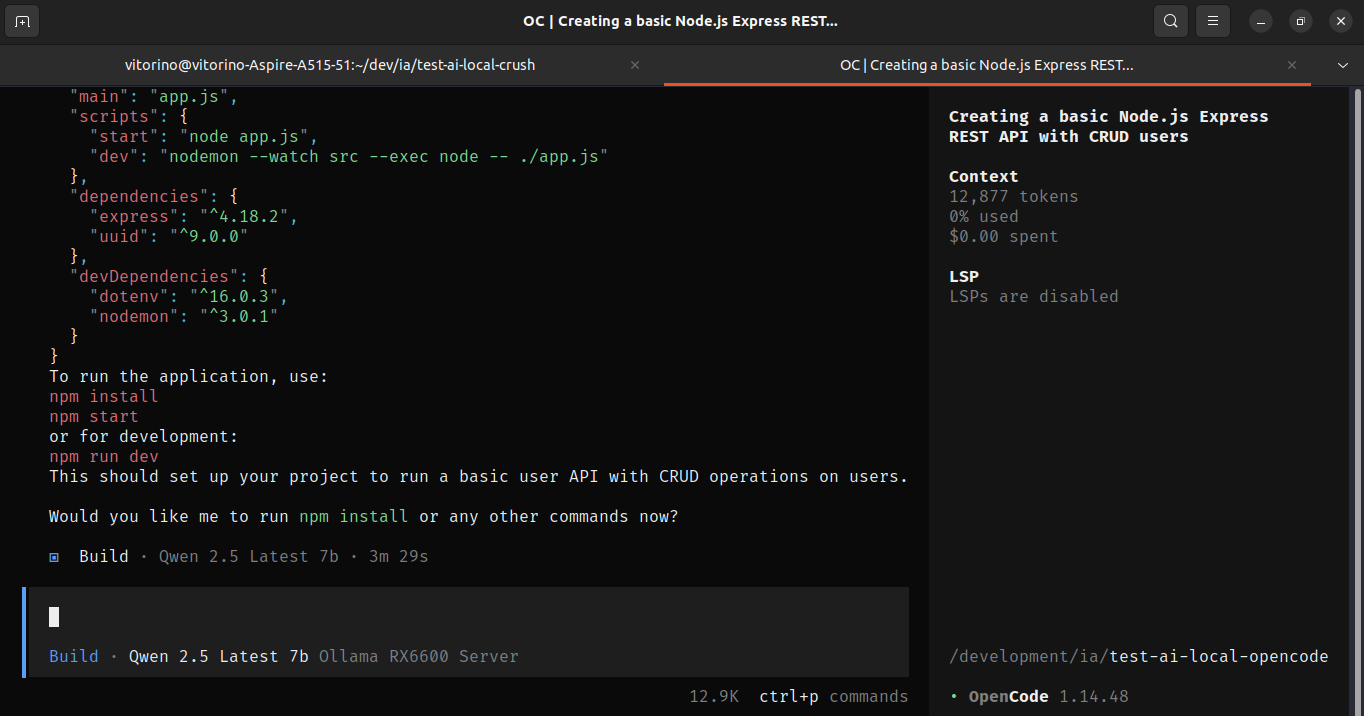
Crush
O primeiro problema foi de compatibilidade: o Crush enviou "think": true no payload para o Ollama, que retornou 400 Bad Request com {"error": "\"qwen2.5-tuned:latest\" does not support thinking"}. Nos logs do crush-qwen2_5.log o erro é imediato — response_status: 400, latency_ms: 31 — o agent nem chega a executar. Tentei com modelos 14B que tinham suporte declarado a thinking no hub do Ollama, mas o tempo de inferência local era inviável para continuar a sessão. Por isso não fui adiante.
O interessante é que o system prompt do Crush nos logs está completo mesmo na requisição que falhou. Dá pra ler toda a filosofia do agent: BE AUTONOMOUS, Don't ask questions, Keep going until query is completely resolved. O workflow interno é explícito: search codebase → read files → identify changes → edit → run tests → fix failures → continue until done. O Crush não pergunta, não planeja em voz alta, não descreve o que vai fazer — ele age.
Isso aparece nos próprios logs de falha: o Crush fez duas requisições com payload idêntico antes de desistir — retry automático, sem intervenção. O problema é que o erro era em nível de API (thinking não suportado pelo modelo), não de lógica. O agent aplicou o comportamento que o próprio system prompt instrui, mas sem conseguir distinguir um erro irrecuperável de um erro contornável.
O tamanho do system prompt já com prompt_tokens_est: 5477 antes de qualquer tool call mostra o custo da abordagem. O Crush carrega um runtime inteiro de regras operacionais, cobertura de edge cases de edição, estratégias de retry, políticas de segurança — tudo embutido no contexto de cada requisição. Para um modelo capaz de seguir essas instruções, isso potencialmente gera execução muito coerente. Para um 8B local sem thinking, é contexto demais para pouco raciocínio disponível.
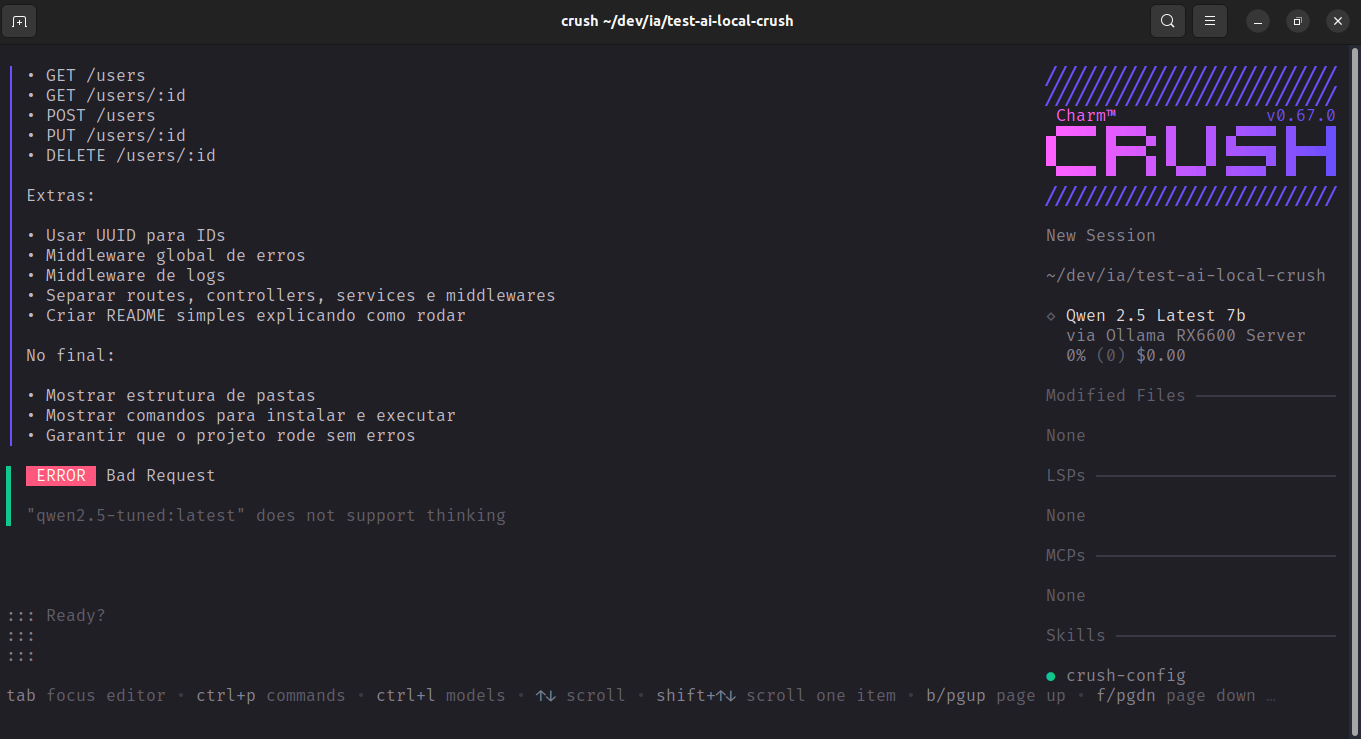
Claude Code
O Claude Code também falhou com o Qwen2.5 via LiteLLM pela mesma razão do Crush: tentou enviar "think": true no payload e o Ollama retornou {"error": "\"qwen2.5-tuned:latest\" does not support thinking"}. Nos logs do claude-litellm-qwen2_5.log o erro aparece duas vezes seguidas — o LiteLLM tentou com agentic_api_call_with_fallbacks, detectou o erro e tentou novamente antes de desistir. Mesmo com retry, sem suporte a thinking no modelo, não teve como continuar.
O que os logs revelam mesmo sem execução bem-sucedida é a magnitude do que o Claude Code esperava do modelo. O system prompt tem dezenas de páginas: definição de subagents (claude, claude-code-guide, Explore, Plan, general-purpose, statusline-setup), schemas JSON completos para ferramentas como Agent e AskUserQuestion, políticas de comportamento, exemplos extensos de uso. O num_predict: 32000 no payload indica que o Claude Code planejava gerar até 32k tokens de saída — ele não estava pedindo uma resposta, estava iniciando uma execução longa.
Há um segundo ponto de falha silencioso nos logs, independente do thinking:
"functions_unsupported_model": [{ "type": "function", ... }]O LiteLLM detectou que o Ollama/Qwen não suporta function calling nativo e moveu as tool definitions para esse campo — as ferramentas seriam passadas como texto no prompt, não como schema executável.
Ou seja, mesmo se o thinking funcionasse, o Claude Code estaria operando sem tool calling real. É infraestrutura de produção embrulhando um modelo local que mal consegue seguir um system prompt de duas páginas.
Não é porque o Crush e o Claude Code não rodaram com modelos locais que eles são piores. Pelo contrário — eles exigiram tanto do modelo que o Qwen2.5 simplesmente não foi capaz de atender. A sofisticação da orchestration pressupõe um modelo com capacidade de reasoning avançado. O erro de compatibilidade com thinking não é um bug de configuração — é o agent revelando sua dependência real do modelo subjacente.
O que um agente mínimo realmente faz
Para entender o ciclo por baixo, montei um ai-runtime bem direto ao ponto: extrai uma keyword do input, roda um ripgrep no projeto para puxar arquivos relevantes, injeta esse contexto num prompt fixo e manda para a LLM. Sem loop, sem ferramentas, sem memória — só o fluxo central funcionando. Não é um agente, mas foi suficiente para entender onde cada parte influencia o resultado e por que agentes reais precisam de tanta coisa em volta disso.
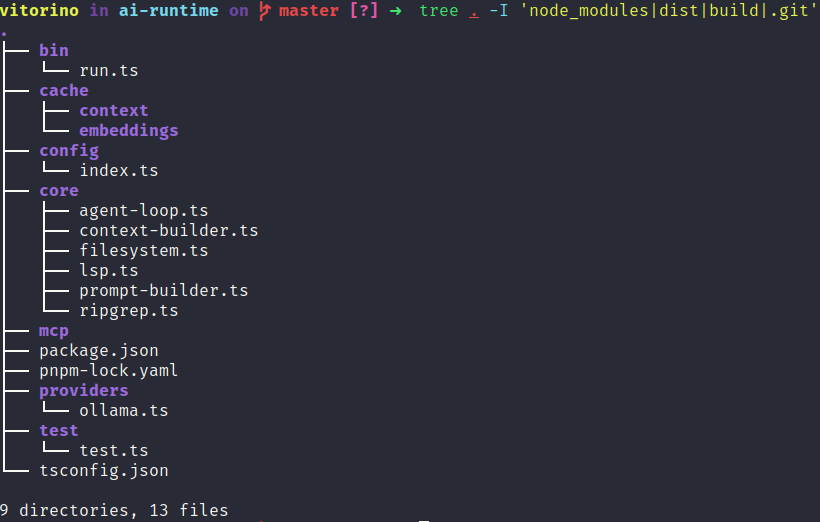
O que os logs dos agents mostram é exatamente a expansão desse fluxo mínimo: o Aider adiciona protocolos rígidos de output para garantir patches aplicáveis; o OpenCode adiciona tool calls concorrentes e compressão de tokens; o Crush adiciona retry loops e execução contínua; o Claude Code adiciona orquestração multi-agent e infra de middleware. Cada camada resolve um problema real que aparece quando você tenta usar o ciclo básico em projetos reais.
Usando LLMs pagas no dia a dia
No uso diário, faço uso constante de agentes com LLMs pagas — inclusive este blog foi criado com elas.
É possível testar outros modelos via OpenRouter. A escolha de qual modelo usar — e se via token ou assinatura — fica a critério de cada um. Não vou sugerir modelo específico porque isso muda rápido e depende muito do caso de uso. Testei também IDEs integradas como Cursor, que adicionam uma camada de UX sobre o mesmo ciclo de agent que analisei aqui.
O que aprendi nesse processo: independente da ferramenta e do modelo, o resultado depende diretamente de quem usa. Quanto melhor descrita e desenhada a solução, melhor o modelo consegue gerar código coerente. Código ruim vai aparecer mesmo em modelos melhores se o pedido for vago ou mal estruturado.
A revisão é responsabilidade do programador. Seguir uma boa arquitetura, declarar arquivos com contexto rico, ir além do AGENTS.md — tudo isso impacta o output final. A camada mais importante não é o modelo — é o contexto que você constrói
em volta dele.
Organizo o contexto do projeto numa pasta .ai/ com arquivos .md separados por propósito: contexto geral, decisões de arquitetura, prompts recorrentes, regras e workflows. Isso merece um post separado — mas é o que faz a diferença entre um agente que acerta e um que erra consistentemente.
.ai
├── context
│ ├── architecture.md
│ ├── conventions.md
│ ├── data-flow.md
│ ├── design-system.md
│ └── stack.md
├── decisions
│ ├── components.md
│ ├── data-fetching.md
│ ├── state.md
│ └── validation.md
├── prompts
│ ├── component.md
│ ├── feature.md
│ ├── refactor-engine.md
│ ├── refactor.md
│ ├── review.md
│ └── test.md
├── README.md
├── rules
│ ├── anti-patterns.md
│ ├── code-style.md
│ ├── hook-rules.md
│ ├── RULES.md
│ └── strict.md
└── workflows
├── bug-fix.md
├── component.md
├── feature.md
├── i18n.md
└── testing.mdEste blog está na minha VPS e foi um exemplo prático disso. Instruí o agente com LLMs pagas para implementar internacionalização, renderização segura de markdown, tempo de leitura, índice, gerador CLI, SEO — entre outras coisas. Não é na primeira execução que ele monta tudo com perfeição, mas com contexto bem estruturado o resultado converge mais rápido. Esse processo, junto com a configuração da VPS e o deployment, fica para outro post.